Ubicación de un centro logístico para operaciones portuarias
Una empresa de logística portuaria pretende crear un centro logístico nuevo que sirva a sus actividades en los puertos de Huelva, Sevilla, Cádiz y Algeciras. Las mercancías se mueven con camiones entre los puertos y el centro logístico y se deben cumplir los siguientes requisitos de optimización de la ubicación:
el centro logístico debe estar ubicado en una zona industrial;
debe estar comunicado con los puertos objetivo por carreteras de alta capacidad;
debe estar lo más central posible a los puertos, pero teniendo en cuenta el volumen de mercancías que se mueven anualmente en cada uno de ellos.
Nuestra información de partida es:
una capa de instalaciones portuarias (it01_puerto.shp);
una capa de usos del suelo (us01_usos.shp);
una capa de carreteras (vc01_1_carretera_arco.shp).
Selección de los puertos objetivo
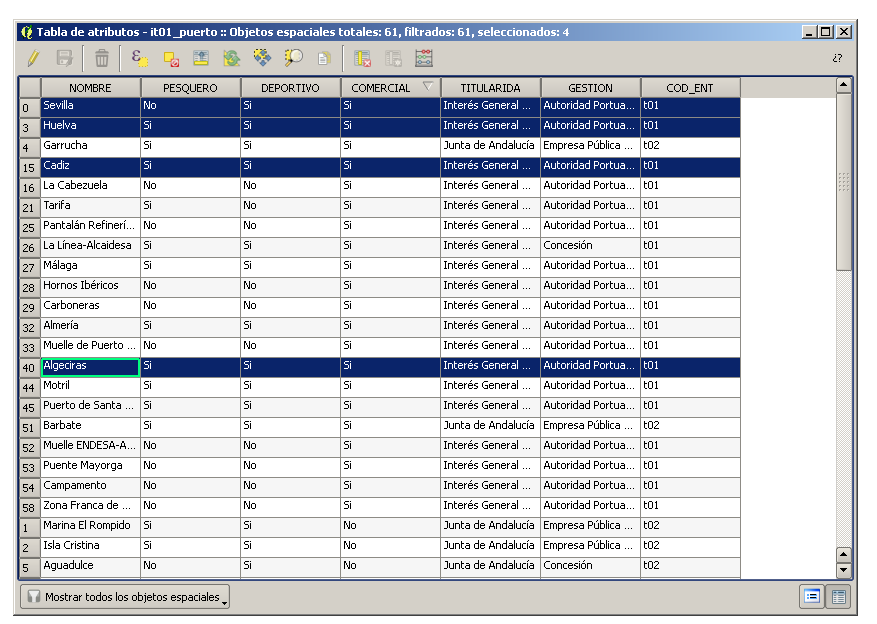
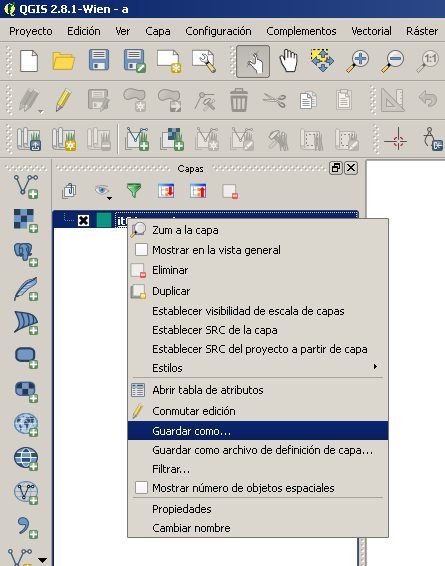
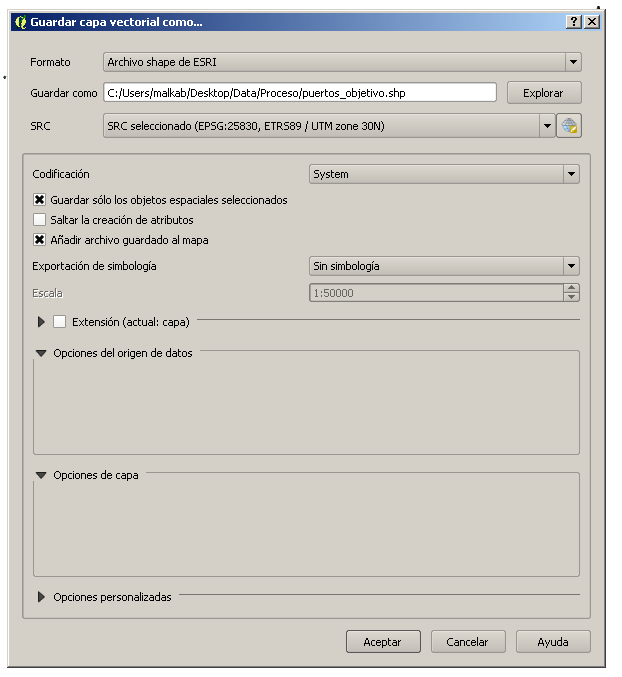
Cargamos la capa it01puerto.shp y abrimos su tabla de atributos, buscando los puertos comerciales de Huelva, Sevilla, Cádiz y Algeciras. Los seleccionamos y los aislamos en una nueva capa llamada _puertos_objetivo.shp para más comodidad.
Para delimitar el área de estudio a una zona razonable, vamos a crear una zona de influencia (buffer) de 50 kilómetros alrededor de cada puerto. Utilizaremos la herramienta QGIS > Vector geometry tools > Fixed distance buffer.

Crearemos a partir del buffer una capa nueva que llamaremos zona_interes.shp. Comprobar su sistema de referencia.

Selección de las carreteras de alta capacidad
Para seleccionar las carreteras de alta capacidad, haremos una selección sobre la capa vc01_1_carretera_arco.shp buscando las categorías RIGE e INT en el campo JERARQUIA.


Al igual que hicimos con los puertos, esta selección la aislaremos, por comodidad, en una nueva capa que llamaremos carreteras_aptas.shp.

Para más comodidad, recortaremos las carreteras seleccinadas con la herramienta QGIS > Vector overlay tools > Clip con la capa zona_interes.

Crearemos una capa llamada carreteras_aptas_clip.shp.


Selección de usos del suelo
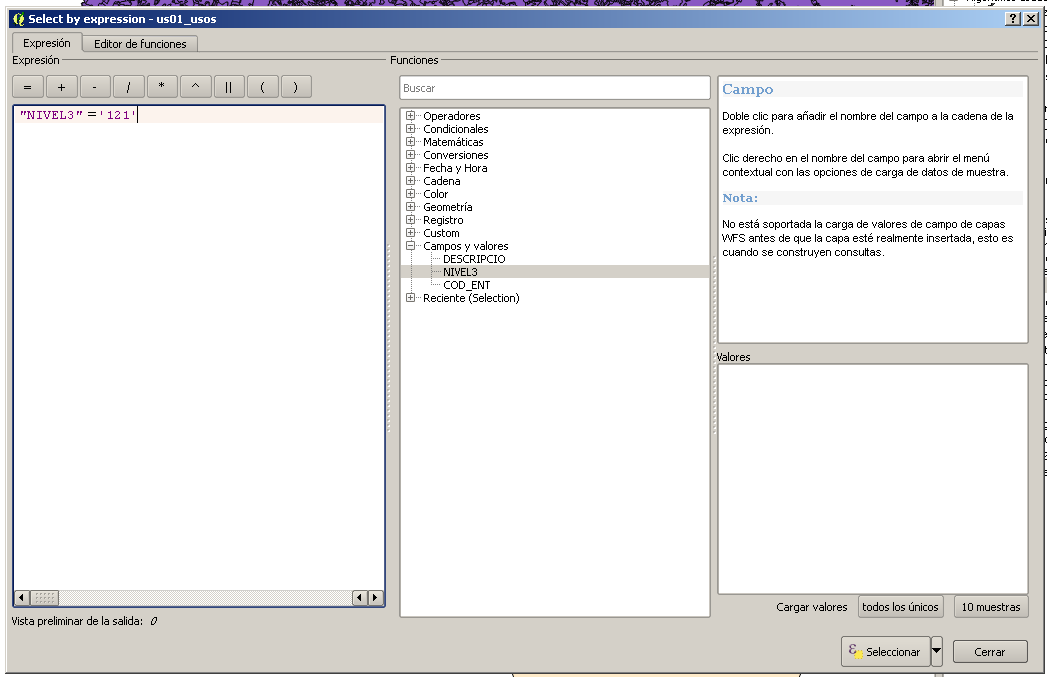
Seleccionaremos de la capa us01_usos.shp los usos del suelo que correspondan con zonas industriales. Dicha capa tiene un campo llamado NIVEL3 con un código numérico de tres cifras. Dichos códigos son códigos del programa europeo para cobertura de uso del suelo CORINE-LANDCOVER, que utiliza una clasificación jerárquica para dicha clasificación. La categoría que se corresponde con las zonas industriales es la 121, así que seleccionamos dicho uso con la herramienta de selección.
Dicha selección la salvamos en una nueva capa llamada zona_industrial. A dicha capa le realizamos, al igual que a las carreteras, un clip con la capa zona_interes, a la que llamaremos zona_industrial_clip. Los usos del suelo son multipolígonos agrupados por categorías, pero como nos interesa cada zona industrial por separado, utilizaremos la herramienta Multipolygon to singlepolygon para convertir el multipolígono en polígonos simples. Llamaremos al resultado de esa capa, de nuevo, zona_industrial.
Tratamiento del coste de tránsito a través de carretera
Hemos de calcular o estimar de alguna manera cuantitativa el coste de movimiento de los camiones por carretera. Comenzaremos por una fricción clásica por distancia para ir matizando dicha fricción en función de otros parámetros.
Creamos en carreteras_aptas_clip.shp un campo nuevo de tipo entero llamado friccion. Seleccionamos las carreteras de tipo RIGE (las de mayor capacidad) y le asignamos una fricción de 1. Seleccionamos después las de tipo INT y les asignamos una fricción de 3. Esto modeliza el hecho de que moverse por la RIGE es menos costoso para un camión que hacerlo por la INT.
Sin embargo, matizaremos un poco más. La autovía AP-4 Sevilla - Cádiz es de peaje, así que la penalizaremos con más fricción. Seleccionamos los tramos de carretera que tengan el campo MATRICULA igual a AP-4 y le añadimos dos puntos adicionales de fricción con la calculadora de campos. Penalizaremos mucho la SE-30 de circunvalación de Sevilla, seleccionando en el campo MATRICULA el valor SE-30 y asignándole 5 puntos adicionales de fricción con la calculadora de campos.
Con esto tenemos un modelo simple de coste de movimiento por carretera. Ahora tenemos que ver el coste acumulado por distancia de tránsito desde cada uno de los puertos objetivo.
Para ello, vamos a utilizar técnicas ráster de la librería de geoprocesamiento del venerable GRASS, antipático como pocos pero el más potente, sobre todo en ráster. Con la herramienta v.to.rast.attribute vamos a rasterizar la capa carreteras_aptas_clip.shp en función del campo friccion, con 500 metros de resolución y amplitud del ráster coincidente con la capa zona_interes.shp. Con ello conseguiremos una capa ráster que llamaremos coste_carreteras. Comprobamos el sistema de coordenadas y aplicamos una semiología que nos permita observar los costes de fricción para cada tramo de 500 metros de carretera.
Ahora tenemos que enganchar los puertos objetivo a la red de carreteras rasterizada que acabamos de crear. Como son polígonos, no pueden hacerlo directamente, así que los abstraeremos con puntos que situaremos manualmente sobre la red ráster de carreteras en su punto más cercano. Creamos por tanto una capa nueva vectorial llamada puntos_puertos con un campo puerto en el que introduciremos el nombre del mismo. Digitalizamos cuatro puntos representando a cada uno de los puertos, teniendo mucho cuidado de que dichos puntos caen dentro de un píxel del ráster de coste_carreteras.
Ahora tenemos que calcular el coste de tránsito acumulado para cada puerto a lo largo de la red de carreteras. Para ello utilizaremos un módulo de GRASS llamado r.cost.full. Seleccionamos primero el puerto para el que vamos a calcular el coste acumulado con la herramienta de selección y lanzamos la herramienta, seleccionando como capa de coste unitario coste_carreteras y como punto de comienzo de cálculo de coste puntos_puertos. Al estar seleccionado uno de ellos, sólo dicho puerto intenvendrá como origen del coste. La resolución del ráster resultante será también de 500 metros y como extensión seleccionaremos otra vez la capa zona_interes. Esta configuración la repetiremos para todos los ráster que creemos a partir de ahora.
De esta manera, crearemos cuatro capas ráster, una por cada puerto, a las que llamaremos coste_huelva, coste_sevilla, coste_cadiz y coste_algeciras. Debemos comprobar el sistema de coordenadas de cada uno de ellos y establecerlo en caso necesario en el EPSG:25830, ya que a GRASS le cuesta comunicarse con QGIS en este aspecto aún. Le damos una semiología apropiada y veremos cómo se distribuye el coste acumulado para cada puerto.
Si sumáramos ahora los costes parciales calculados, tendríamos una muy buena medida de centralidad en la red, encontrando los puntos de menor coste acumulado entre Sevilla y Cádiz. Sin embargo, tenemos que ponderar los costes porque no es lo misma la actividad que genera para la compañía el puerto de Algeciras que el de Huelva. Cada puerto mueve al año toneladas de mercancía por estos valores:
- Algeciras: 190.000 Tn;
- Sevilla: 120.000 Tn;
- Cádiz: 70.000 Tn;
- Huelva: 25.000 Tn.
Por lo tanto, dado que Algeciras y Sevilla van a generar la mayor cantidad de tráfico de camiones dentro de la compañía, tiene sentido que modelicemos este peso relativo a la hora de tener en cuenta la ubicación óptima a lo largo de la red.
Por lo tanto, creamos un nuevo campo decimal en puntos_puertos llamado tonelaje e introducimos los datos anteriores. Creamos otro que llamaremos coef_coste, decimal, y con la calculadora de campos introducimos la siguiente fórmula sencilla:
coeficiente coste = tonelaje puerto / máximo de tonelaje en cualquier puerto
Con lo que los valores de ponderación del coste acumulado de tránsito para cada puerto será:
- Algeciras: 1;
- Sevilla: 0.63;
- Cádiz: 0.36;
- Huelva: 0.13.
De esta manera, una distancia grande desde el puerto de Huelva (poca actividad) penalizará menos que una gran distancia desde el puerto de Algeciras (muchísima actividad), con lo que la centralidad en la red se decantará hacia Algeciras alejándose de Huelva.
Para realizar el cálculo final de coste (álgebra de ráster), utilizaremos la herramienta r.mapcalculator de GRASS. En ella seleccionaremos las cuatro capas de coste acumulado que hemos calculado para cada puerto:
- capa A: Algeciras;
- capa B: Cádiz;
- capa C: Huelva;
- capa D: Sevilla;
introduciendo en el campo Formula la expresión acumulada ponderada:
A+(2.71*B)+(7.6*C)+(1.58*D)
Creamos la capa coste_total. Chequeamos sistema de coordenadas y le damos semiología, descubriendo que la centralidad ponderada en la red se ha desplazado entre Cádiz y Algeciras.
Asignación del coste a cada zona industrial
Con la herramienta de GRASS r.to.vect vamos a convertir cada píxel del ráster coste_total en un punto que lleve el valor del coste acumulado ponderado en ese tramo de carretera. El resultado de dicha herramienta lo llamaremos puntos_coste, y en dicha capa crearemos un nuevo campo al que llamaremos id y que, con la calculadora de campos, igualaremos a la expresión $id, consiguiendo con ello un campo numérico único para cada punto de coste. Como siempre, comprobaremos el sistema de coordenadas y representaremos para comprobar visualmente que lo que hacemos tiene sentido.
Ahora tenemos que hacer un análisis de proximidad que empareje las zonas industriales con el punto de coste acumulado ponderado más cercano en la red de carreteras. Para ello, primero tenemos que convertir las zonas industriales a puntos. Lo haremos calculándoles el centroide con la herramienta QGIS > Vector geometry tools > Polygon centroids. Crearemos una capa zona_industrial_centroide a la que le, de forma análoga a cómo hicimos con puntos_coste, crearemos un campo id que igualaremos a $id para obtener un campo numérico único que nos sirva de clave.
El cálculo de proximidad entre los centroides de zona_industrial_centroide y puntos_coste lo haremos con la herramienta Vectorial > Herramientas de análisis > Matriz de distancia, situadas en los menús de QGIS. La capa de entrada será zona_industrial_centroide, mientras que la capa de destino será puntos_coste. Utilizaremos la primera opción de cálculo, matriz de distancia lineal, y seleccionaremos abajo que sólo queremos quedarnos con el punto más cercano de todos. La herramienta nos devuelve un texto delimitado por comas (CSV) que llamaremos matriz_distancia.csv.
Añadimos dicho CSV al proyecto con la Capa > Añadir capa > Añadir capa de texto delimitado, ya que es la forma de que el programa reconozca los campos numéricos como tales y no cómo carácteres. En las propiedades de la tabla zona_industrial_centroide creamos una unión de tablas con matriz_distancia entre los campos id_input e id. Para fijar el ID del punto de coste más cercano que le corresponde a cada zona industrial creamos un nuevo campo en zona_industrial_centroide llamado id_p_coste que igualamos al campo id de la matriz. Podemos ahora deshacer la unión de zona_industrial_centroide con matriz_distancia.
Por último, ya sólo nos queda hacer una nueva unión entre zona_industrial_centroide y puntos_coste en función de los campos id_p_coste e id. De esta manera ya tendremos relacionados los datos de cada zona industrial con los del punto de coste acumulado ponderado en carretera más cercano, pudiendo proceder a la selección de la zona industrial más competitiva en función de otros parámetros no ya geográficos.